
自动驾驶为何青睐人工智能?
无论你是怎么认知自动驾驶的,但是相信我,如果你深入体验过哪怕是L2级别的辅助系统,都会留下深刻的印象。
自动驾驶近几年的火热,除了因为技术条件“相对成熟”和厂商作为宣传亮点,另一个重要原因是基于现在的行驶环境,自动驾驶成为了改善驾乘体验和解决道路拥堵的“良方”。
改善驾乘体验非常容易理解,指的是可以利用自动驾驶辅助,大大减少驾驶疲劳,或者是未来在行驶路上休息娱乐或者工作学习。而延伸一步则可以转为解决道路拥堵,或者提高车辆利用率,不仅能够给人们节省大量的时间,还能形成规模巨大的经济效应。
前一阵参加奥迪MQ峰会时,有幸聆听到了李开复博士关于“人工智能(AI,Artificial Intelligence)”的演讲。他在AI领域学习工作已有39年,其博士毕业论文题目就是“AI语音识别”,如今他手中有17家行业巨头公司,其中5家专注于AI领域。
演讲中提了两个方面非常有趣,一个是虽然AI已经落地到应用层面,例如语音、人脸识别、医疗领域、物流、自动驾驶等等,但其实这些都属于Narrow AI,只能在某单一领域工作,而像《人工智能》、《Her》等电影中的人工智能机器人,则属于通用人工智能(AGI,Artificial General Intelligence)范畴;另一个则是现在人工智能利用Deep Learning(深度学习)和暴增的数据量,以一种人们不可想象的速度在发展。
尤其在自动驾驶领域,这种进步非常明显。
为什么是人工智能?
要想弄清楚人工智能对于自动驾驶的意义,得先从自动驾驶的发展历史讲起。
关于自动驾驶系统方面的实验,最早可以追溯至1920年代,第一个关于自动驾驶的概念车于1939年纽约世界博览会的未来世界展示区域亮相,由通用公司打造,不过直到1950年代才真正出现可行性方案,1958年,通用公司终于拿出了一辆能够依靠道路上的“金属钉”和无线信号传输指引的自动驾驶车辆(通过道路金属钉给予定位信息,再由外界处理信息将指令传入车辆使其保持车道居中行驶)。
1977年,一辆半自动驾驶车辆被日本筑波机械工程实验室(Tsukuba Mechanical Engineering Laboratory)研发出来,除了需要配合特殊的路段之外,车辆本身还结合了2个摄像头和一台模拟电脑。只不过,这台半自动车辆的最高时速仅有30km/h,且必须借助于高架轨道才能实现。(除了依靠道路信息补充,车辆开始拥有自己的实时信息处理能力)
真正自动驾驶车辆的出现是在1980年代,一部分来自卡耐基梅隆大学于1984年开始的Navlab和ALV项目,由DARPA(Defense Advanced Research Projects Agency,美国国防高级研究计划局)提供资金支持,另一部分来自于1987年开始的梅赛德斯·奔驰与慕尼黑联邦国防军大学(Bundeswehr University Munich)合作的EUREKA Prometheus项目。1985年,ALV项目展示了能够在两车道宽的正常道路以31km/h时速自动驾驶的车辆,并于随后两年先后加入了躲避障碍的功能和白天夜间的越野功能。
被作为里程碑式进步的是,Navlab项目在1995年用5号实验车完成了从宾夕法尼亚州匹兹堡到加利福尼亚州圣地亚哥的海岸公路行驶(4585km),其中98.2%的路程(4501km)完全是由自动驾驶完成(均速102.7km/h)。而这一伟大的成绩,直到在2015年才由德尔福改造的奥迪车型所打破,这辆车完成了以99%自动驾驶率跨越15个州,共计行驶了5472公里。也是在同年,美国内华达州、佛罗里达州、加利福尼亚州、维吉尼亚州、密歇根以及华盛顿,开放条例允许在公共道路上持牌进行自动驾驶车辆测试。
但上述这些车辆都处于实验性质,并没有考虑实用性和民用可能,属于对于技术的探究。而让大部分人认识和体会到自动驾驶魅力的,是2014年特斯拉引进Autopilot功能(依靠8个摄像头、12个超声波雷达、1个毫米波雷达),NHTSA统计数据显示,即便在那时功能不完善的AP系统中,也能够以76%准确率预测碰撞发生可能并避免90%以上的预测碰撞事故。
如果仔细观察这些发展里程,有一个很明显的发展趋势,自动驾驶功能越来越不依靠外部信息处理辅助,而转向“单体智能”的方式发展。
为什么会这样,原因很简单,因为目前绝大多数道路建设、交通法规,甚至是城市建设都是基于“人类开的车”发展形成。在5G助推下的V2X模式固然好,但无论是基建的财力投入,还是时间的长度,都并非是短期可以投入实用的模式。也就是说,如果没有“神奇的魔法”让所有车辆换成类似电影中的自动驾驶车辆,那么势必意味着想要适应当下环境实现自动驾驶,要靠“自己”。
“单体智能”中,或许有人认为电脑是最强的,但实际上“人脑”才是最强的。人类大脑换算电功率约等于20瓦,相比之下,一个同等强大的计算机的功率约是2400万瓦。Tim Hanson教授把大脑称为“已知的信息密度最大、最有结构性,并且最能够自我构建的物质”。更关键的是,大脑处理信息的方式与普通电脑不同,人类可以进行抽象思考、联想、自我学习等等。但传统的编程,无法做到自适应升级的,发生在道路上的事有无穷尽的可能,以“有限”应对“无限”,显然是走不通的。
所以,“类人”处理模式的人工智能,成为了推动自动驾驶发展的核心技术。
什么是人工智能?
6亿年前的生物没有任何神经结构,不能思考或者处理信息,一生的目标就是等待死亡。直到5.8亿年前水母出现,水母拥有世界上最早的神经系统——一个神经网,能够从周围环境收集重要信息,通过神经网处理后,做出反应。也就是为了生存,拥有了收集和处理信息的能力。
5.5亿年前,扁形虫出现,通过神经收集信息后,能够传递给它的头部(世界上最早的脑,世界上最早的中枢神经系统),进行统一决策,而非单纯的对信息直接做出反应。2.65亿年前,青蛙出现,2.25亿年前哺乳动物老鼠出现,随着动物自身结构和周围环境愈发复杂,原本脑结构已经不足以处理各类“需求”了,例如于是在原有脑基础上,形成了另一个“指挥中心”——世界上最早的边缘系统(Limbic system)。
再后来,随着猴子和原始人的出现,皮质(Cortex)在脑中应运而生,它能够实现“思考”,能够产生复杂的想法、通过缺失的信息来推导想象、制定长期规划等等功能。
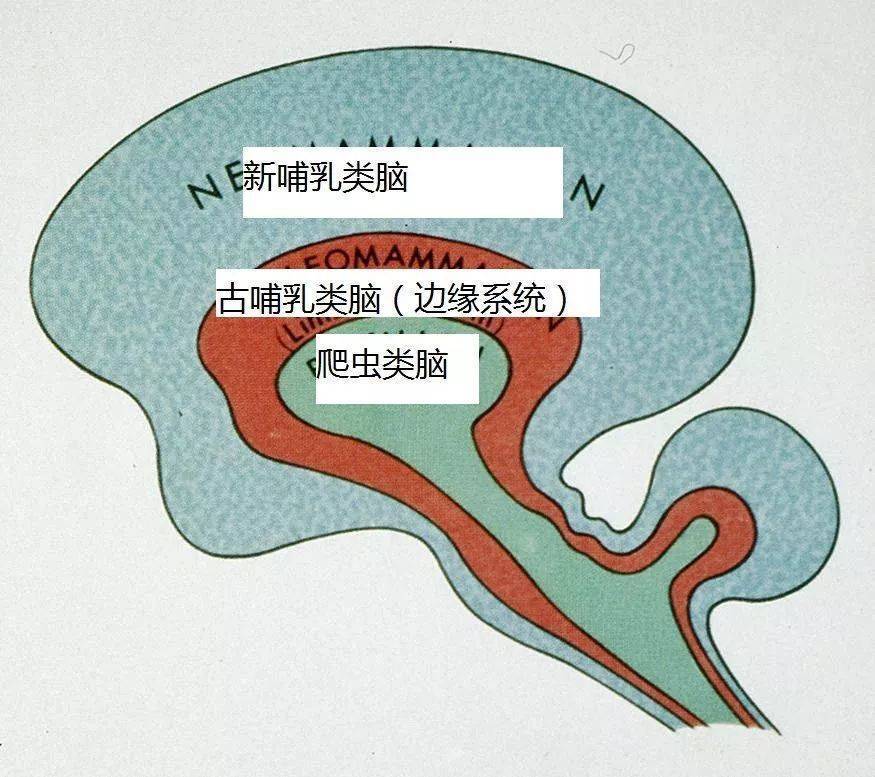
(图来自《人类唯一的出路:变成人工智能》,最外层皮质、其次边缘系统、最内侧是脑干和小脑)
本质上,如果没有皮质,人类跟青蛙差不多,再去掉边缘系统,就跟爬虫差不多了。这也就是为什么人脑中灰质和边缘系统在整个大脑中排名第一“聪明”和第二“聪明”,因为他们分别应对着极为复杂和复杂的需求。其他多负责基础生存所必须的反应和传输信息等功能,例如呼吸、心脏跳动等维持生命的功能,和将身体各处神经传来的信息分配给指定的功能区。
皮质负责几乎所有“人”的事情,看到、听到、感觉到的事物,语言、运动、思考、计划甚至性格都由这里来处理,也就是人类智慧的根基。边缘系统就是一套为生存而生的系统,所有与生存相关的都由此控制,同时这里也是情绪产生的地方,因为情绪也决定着生存。所以本质上,你如果有过脑袋里俩个打架的“小人”出现,那么皮质就是“理智”,而边缘系统就是“欲望”,但边缘系统往往占主导地位,也就是边缘系统指挥着皮质工作。
额叶就处于皮质中,它掌管你的人格,以及很多思考相关的东西,比如理论、计划和执行功能。你的很多思考,是在额叶的前端进行的,这部分叫作前额皮质(prefrontal cortex)。前额皮质是那些内心斗争中另一个会出现的角色,那个理性的决策者,那个推动你好好做事的人,那个告诉你不要在意别人想法的真诚的声音,那个希望你能有大格局的领路人。
曾获得诺贝尔奖的“额叶摘除手术”非常出名,摘除1/3额叶,用于治疗精神病,不过后来被评为恶魔的荒唐行径,因为摘除之后,这个人与“行尸走肉”毫无区别。
人脑虽然“算力”很高,但其实与普通电脑的运行模式不同,尤其是浮点运算(例如算术),简单估算人脑比计算机慢1000万倍,但慢不代表“笨”,比如你算不出骑自行车时候所有的加速度和速度数字,但是你能很稳地骑行。
计算机处理信息多数以连续串行模式,而人脑不同,大约有150~200亿的神经元在皮质中,这些神经元结构能够同时向所有其他神经元发送信号,也就是说是以并行结构处理信息的。所以你处理信息是网状结构,是相互关联影响的,比如你走在路口,看到一辆车在大晴天突然打开了雨刷,你立马就知道这个人是要拐弯,这个处理过程交给普通电脑是无法完成的。
(大脑3%左右的神经元和0.0001%神经突出结构渲染图)
所以人工神经网络诞生了,其最初的目标是希望模拟人脑结构,打造一套系统,以达到与人脑相同的方式解决问题,不过后来由于技术限制,逐渐背离了原本生物学的初衷,转而利用这套方法专注于执行特定的任务。
这套系统最大的能力,就是学习。
人工智能其实是个大范畴,定义很多,总结来说就是指的像人类一样的工作模式,也就是模拟人的思维过程和智能行为(学习、推理、思考、规划等等),只不过由于技术的限制,目前人工智能只能实现学习能力。而深度学习则是一种方式,是适用于神经网络这种“设备”的机器学习方式中的一种。
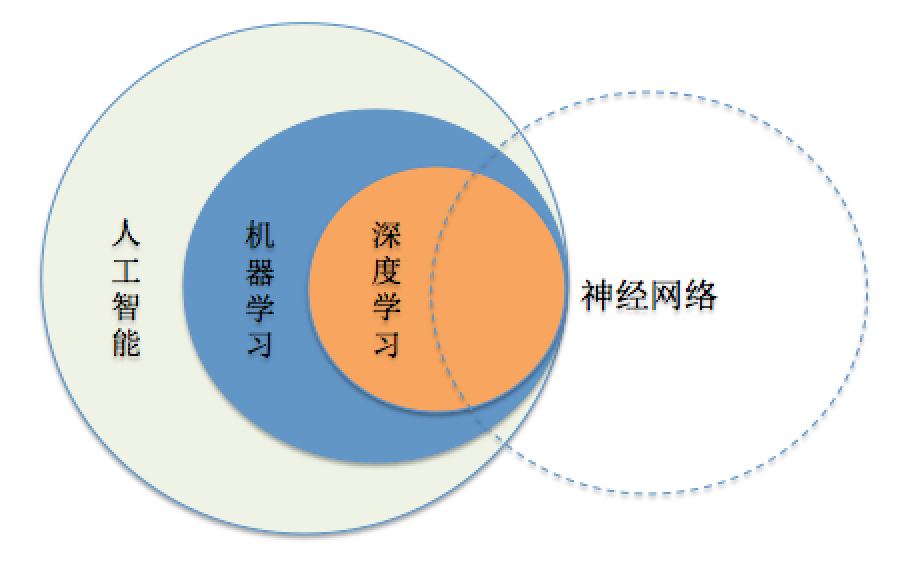
(三者之间大致关系,人工神经网络是被人工智能所用,其本质是模仿大脑生物结构的数学计算系统)
通过深度学习方式,训练神经网络,以达到部分人类大脑工作模式的优点——即现在的人工智能。
神经网络与深度学习
归根结底,目前AI落地的应用,利用的就是深度学习的方法,将原本“有限”的编程方式,转变为能够自我升级成“无限”的解决方式,以应对“无限”的问题。
艾伦·麦席森·图灵(Alan Mathison Turing),英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父。1931年图灵进入剑桥大学国王学院,毕业后到美国普林斯顿大学攻读博士学位。1936年,图灵向伦敦权威的数学杂志投一篇论文,题为“论数字计算在决断难题中的应用”。在这篇开创性的论文中,图灵给“可计算性”下了一个严格的数学定义,并提出著名的“图灵机”(Turing Machine)的设想。“图灵机”不是一种具体的机器,而是一种思想模型,可制造一种十分简单但运算能力极强的计算装置,用来计算所有能想象得到的可计算函数。
1950年,图灵发表了一篇划时代的论文,文中预言了创造出具有真正智能的机器的可能性。由于注意到“智能”这一概念难以确切定义,他提出了著名的图灵测试:如果一台机器能够与人类展开对话(通过电传设备)而不能被辨别出其机器身份,那么称这台机器具有智能。这一简化使得图灵能够令人信服地说明“思考的机器”是可能的。
1952年,在一场BBC广播中,图灵谈到了一个新的具体想法:让计算机来冒充人。如果不足70%的人判对,也就是超过30%的裁判误以为在和自己说话的是人而非计算机,那就算作成功了。
这就是人工智能界著名的图灵测试。
1943年Warren McCulloch和Walter Pitts曾写过论文讲述人工神经网络该如何工作,并且利用电路造了一个简单的模型。后来经过诸多人的努力和研究发展,直到1998年,斯坦福大学的Bernard Widrow和Marcian Hoff才打造出了第一套用于解决实际问题的人工神经网络。
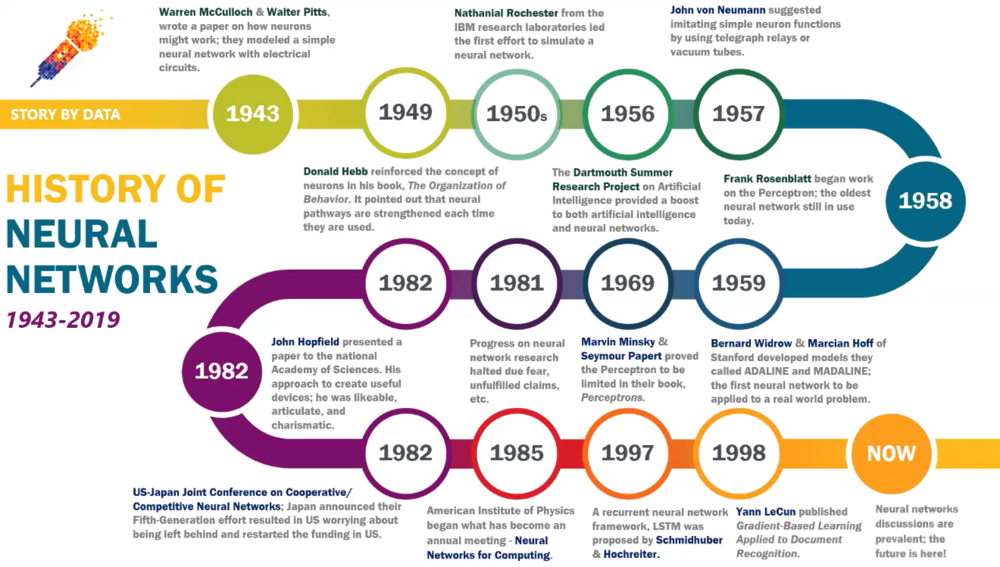
1956年,达特茅斯夏季会议上各路大牛提出了AI定义,大大推动了AI和人工神经网络的发展,也被广泛人为是AI元年。当时人们信心满满,认为不用20年就能打造出跟人脑差不多一样的AI系统。结果在不断研究中发现,深度神经网络的算法太过复杂,从而无从下手。于是放弃了当初“大而全”的目标形式,转为以执行单一目标为方向。
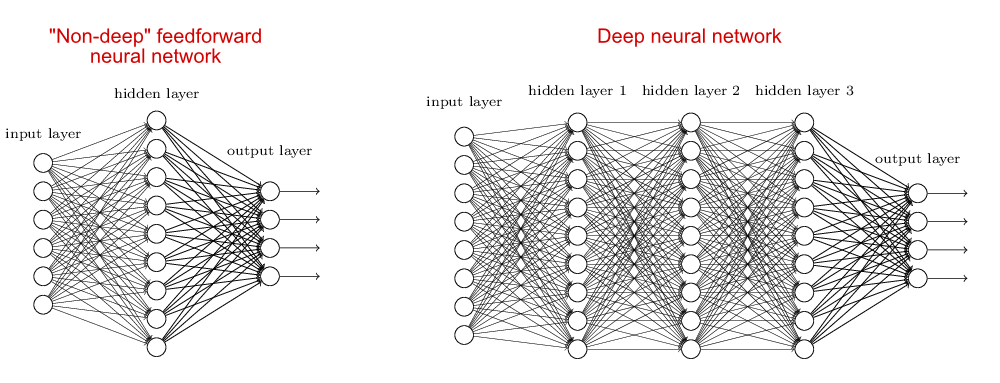
(左侧为一般神经网络模型,右侧为深度神经网络模型)
深度学习的概念就起源于对人工神经网络的研究,利用深度神经网络实现模拟人脑分析学习的方法(算法)。最早是1965年,由Alexey Ivakhnenko和Lapa发布了一个通用学习算法,后在1971年发表论文描述了利用该算法对8层深度网络进行训练。后来通过不同人的努力,不断有新的深度学习算法出现,适用于解决不同的问题。
传统的机器学习方式,是利用复杂的高阶函数,将问题转变为二维、三维、甚至是几万维的高维空间,将数据能够分散开来利于处理。但是无论数学家和科学家如何努力,创造多么聪明的建模方式,但是建模就意味着有局限性,都很难真正模拟世界万物的特征规律。而深度学习则跳出了这个思维,虽然也是将数据升维变为多维空间,但处理方式却完全不同。
深度学习将一大堆数据丢进一个复杂的、多层级结构的深度神经网络(一般人工神经网络没有中间隐藏层,有1~n个隐藏层就称之为深度神经网络),然后直接检查经过这个网络处理得到的结果数据是否符合要求。如果符合就保留这个网络为目标模型,如果不符合,不断调整每个部分的具体参数,直到输出满足要求为止。换句话说,深度神经网络隐藏层中发生了什么,至今没有人能完全说的清,就像是一个“黑盒”,也就是说无法准确详细的弄清楚每一次的调节对最终结果产生着什么样的绝对因果关系。
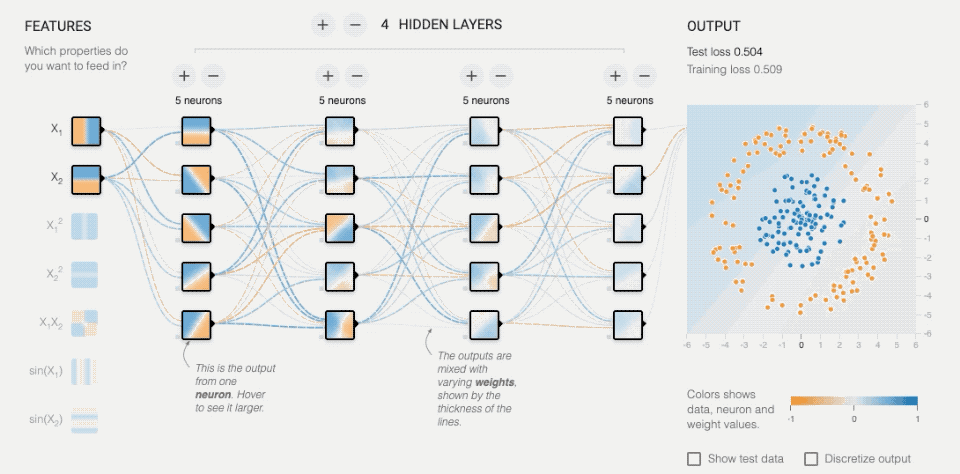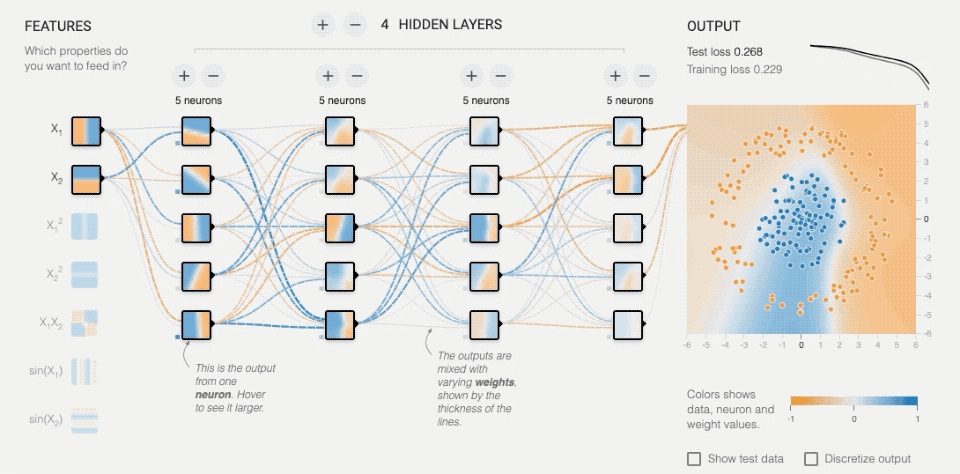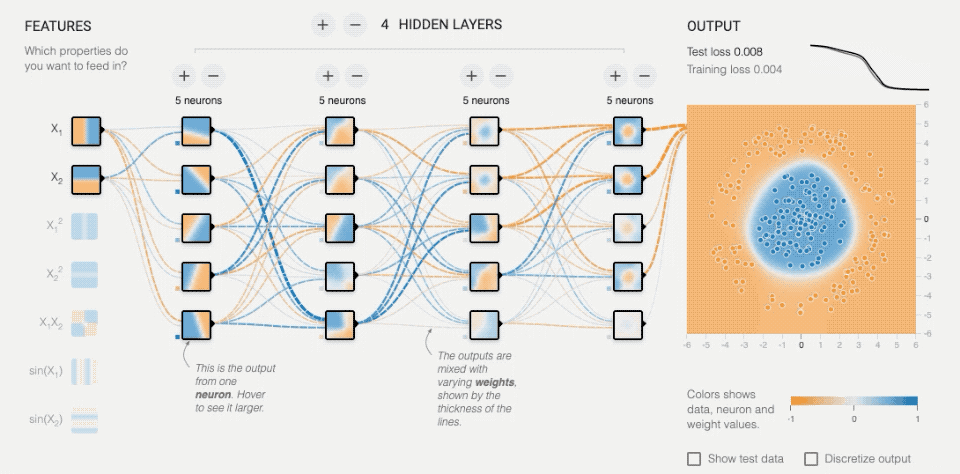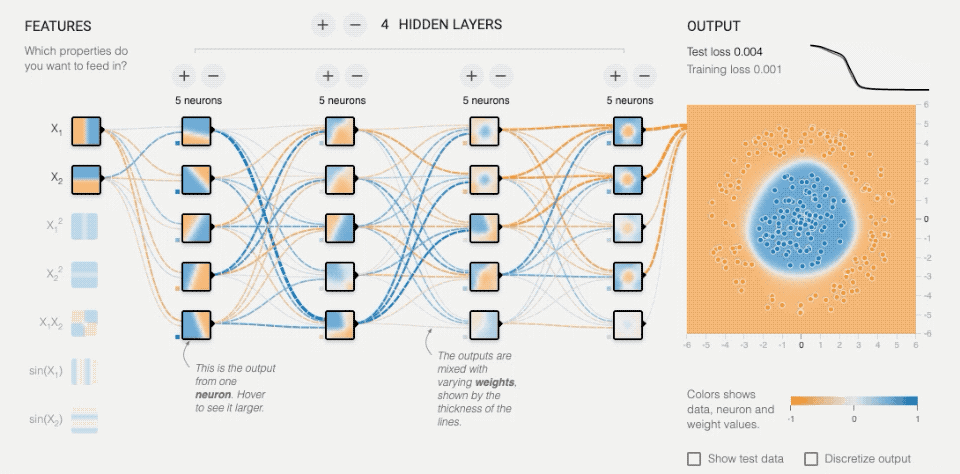
(利用http://playground.tensorflow.org/开放的神经网络模拟器进行演示)
上图用了4层隐藏层,每层5个神经元节点,右侧的点状图是需要识别的图案,最终产生的底图是经过神经网络处理后判断的结果。随着时间训练次数不断增加,可以注意到右上角错误率很快将至0.001,当然这个数据处理比较简单,但原理是一样的。每个神经节点都会随着训练会产生变化,根据最终结果的情况反馈进行“自我修正”,从而导致不同节点的判断比重加高(中间的虚线)。
这与人类的神经结构很像,人类每次的学习认知,都会导致神经系统生理结构的些许变化,当你足够有经验时,几乎不需要什么思考时间,就直接做出反馈,这就是神经元自身找到了最佳“通路”,并且神经元本身甚至可能会变“粗壮”,化学信息产生量会增大,以“适应”某一种情况。
用人类学习过程打个比方,一个事物由许多Pattern或者叫特征,例如苹果,认知苹果的过程大致可以简化为,你看到第一次看到苹果(INPUTS),会接受到颜色的信息,形状的信息,通过颜色信息的组合,通过基础信息又可以进一步知道组合信息,例如颜色的分布、花纹等(HIDDEN LAYER)。当你被告知这个事物叫苹果,你会将特征信息存储对应苹果(OUTPUTS)。
而后如果见到不同颜色不同形状的苹果,或许不会100%确信是苹果,但是经过信息比对,能猜出是苹果的概率很大。再然后,你对此是否为苹果的判断会越来越精准。当然这还是仅仅局限于视觉信息,如果加上触觉、嗅觉等其它信息的参与,其判断结果将更加精准。
越来越多的特征信息存储,大脑会不断拥有更多的特征信息来判断,结果一步一步趋近于正确答案。就好像如果你了解某一车型,或许仅仅看到了进气格栅或者倒车镜,就能精准说出型号一样。这是因为你大脑中储存了太多的相关信息,每一个特征都能不断减少答案备选项。根据外形颜色等,你得知是一辆车,进一步的组合信息得出是某一品牌的车,再根据一些特征交叉判断得知是某一型号的车。
而判断不仅仅局限于物体,例如看到两个人牵手,基础视觉信息判断出是在牵手,而后根据体型信等息得知两人是异性,那么两人的关系可能是父女、母女、情侣或者其它可能,再之后通过样貌判断得出年龄进一步缩减可能,得出两人关系。又或者当两个人相互拳打脚踢,通过具体的神态或者听到之间对话得知信息,就可以预测出他们一会是去派出所还是去喝酒又或者是分手离婚。
也就是说当特征信息输入大脑后,每一个信息判断结果都会有诸多的可能,而通过相互交错影响制约,逐步降低错误结果概率,而在最终待选结果中判断得出可能性最高的,如果通过训练或者教学,得到的答案会越来越接近答案。
这样就意味着需要大量的数据来支撑训练,以及性能强劲的运算力来执行运算。
李开复博士在其博士论文中,做出的语音识别功能,虽然在当时他所采用语音数据库中非常大的,但其实不过仅有100MB,却花费了他导师近10万美刀,在1988年相当于两套房子的价格。而如今大数据时代,各种信息的数字化提供了海量的数据,所以能够支撑起AI的快速发展。
另一个算力的问题,传统设计的CPU芯片并非针对于神经网络计算模式而生,效率极低,不过GPU的数据计算模式相近,所以过去多采用GPU作为AI开发所用。后来单独为此研发了神经网络处理单元(NPU,Neural Processing Unit),当然还有其他类似的名字,例如TPU(Tensor Processing Unit)、NNP(Neural Network Processor)、IPU(Intelligence Processing Unit)等,大大提高了神经网络处理数据的速度。
自动驾驶
绕了这么大一圈,我们回到自动驾驶问题上。
自动驾驶最大的难点其实就是“建立准确的坐标”,也就是以自己为中心,周围所有事物的三维坐标是如何的,决定着自动驾驶能否实现。马斯克曾在采访中说过:“例如GTA5游戏中,AI电脑的汽车如果不是你主动干预冲向它,它能在任何时间都安全地行驶。”
对于车辆的控制对于车企来说早已不是什么难点,例如George Hotz通过一套几千元的设备已经让十几台普通车辆实现了L2级别自动驾驶(此人曾经是特斯拉AP团队一员,后来自己成立了Comma.ai,利用深度学习打造了一套OpenPilot系统,仅仅利用了一些简单设备接入汽车,加上自己打造的算法,改装成L2级别自动驾驶)。
老生产谈一下自动驾驶分级:
SEA Level 0:无自动化。目前已经很难看到Level 0的汽车了,因为任何电子接入帮助你安全的设备都可归于L1级别,所以L0意味着ABS系统都没有
本文系作者授权本站发表,未经许可,不得转载。






